The Workshop: System Management with Ansible php[architect] Magazine December 2019
Joe • August 19, 2020
learning packages phparch writing ansibleWarning:
This post content may not be current, please double check the official documentation as needed.
This post may also be in an unedited form with grammatical or spelling mistakes, purchase the December 2018 issue from http://phparch.com for the professionally edited version.
The Workshop: System Management with Ansible
Ansible is an IT automation tool used for configuring systems and deploying applications. Ansible is open source is supported in the enterprise by RedHat. Ansible communicates over SSH so there is no need to install any extra software on the remote systems. Ansible allows us to version control our infrastructure in YAML files and supports Jinja templates allowing flexibility in how we can configure services and applications. This month we’re going to review Ansible’s core concepts and begin to build our first playbook.
Ansible’s design goals set it apart from similar tools such as Chef and Puppet because there is no Ansible “agent” application to install on the remote systems. Everything is accomplished over SSH which also gives us the advantage of not having to install anything to manage a system. We can simply spin up a cloud Linux server and immediately start configuring the system instead of having to install an agent for Chef or Puppet. The second design goal is is to be highly reliable by building playbooks to be idempotent from the start; meaning you can run a playbook over and over and not harm the system or perform the same work over and over. Ansible will only change state if the existing state is not what is described in the playbook. The last design goal of ansible is a low learning curve. All files which comprise an ansible playbook are predominately YAML. Templates are stored in the Jinja template format which is very similar to Twig templating in PHP. These design goals come together to allow us to build easy to read, secure, and reliable code to manage infrastructure and applications.
YAML is a deal-breaker for many people. If you’ve struggled with YAML in the past due to whitespace issues, try turning on whitespace indicators in your editor so you can visibly tell where your indentions are located.
The core concepts of Ansible can be broken down into nodes, inventory, modules, tasks, and roles. Together these concepts will form a playbook: a collection of files that specify the state the remote system should be in after the ansible process has been completed.
Control & Managed Nodes
A control node is a node from which Ansible is installed and executed. As we’re just learning this will most often be our systems. Once we’re managing more than a handful of playbooks it makes sense to move to Ansible Tower or Ansible AWX, the open-source version of Ansible Tower. These systems allow you to run Ansible playbooks from a centralized system that is located closer to the infrastructure we’re managing to take advantage of lower latency during playbook execution. Tower and AWX would be run on their control nodes. These tools also allow for more powerful scheduling than what we can accomplish on our systems.
Managed nodes are remote systems that we’ll be running Ansible against. This would be your cloud infrastructure, onsite systems, or any combination of the two. Managed nodes are also referred to as “hosts”. We don’t need to install Ansible on managed nodes since everything happens exclusively over SSH connections.
Inventory
Inventory files are how we’ll define our managed nodes. I prefer to use the INI format over YAML, but you can use whichever you’re more comfortable with. Inventory files allow us to group our hosts and we can target hosts from our playbooks by using their group names. If we had a traditional load balancer, two application servers, and a database server the inventory file could be:
[webserver_01]
web-01.domain.tld ansible_host=192.168.42.10
[webserver_02]
web-02.domain.tld ansible_host=192.168.42.11
[webservers]
web-01.domain.tld ansible_host=192.168.42.10
web-02.domain.tld ansible_host=192.168.42.11
[webserver_loadbalancer]
lb.domain.tld ansible_host=192.168.42.9
[database_01]
db-01.domain.tld ansible_host=192.168.42.20
In this example inventory file, we define four different systems comprised of two web servers, a database server, and a load balancer. We’ve grouped them logically so that we can target them individually, or together in their groups. The group name is surrounded by brackets so the web-01 system is in group webserver_01 as well as the group webservers.
A personal preference of mine is to use domain-based naming so that as the playbook is being run Ansible reports these domain names, rather than the different IP addresses so we can easily see which system is being affected during our playbook execution. You could also remove the domains and leave the IP address of the machine(s) in each group.
Ansible also has two default groups “all” and “ungrouped” we can leverage as needed. Most often you’ll use all to tell Ansible to execute against all hosts in the inventory when you want to perform tasks suitable for all hosts such as upgrading packages, configuring a service such as SSH. You could use ungrouped to target any systems defined in the inventory file which do not belong to a group. I tend to avoid this by grouping all hosts in my inventory files. I urge you to group all of your systems as we have done in the example inventory file, think of host grouping like-named routes, by grouping hosts you can then refer them by those group names and you won’t have to worry about updating hosts in different playbooks over time as you add or remove systems, you’ll just keep the hosts up to date in the appropriate groups in your inventory file. This allows us to easily add more webservers to our inventory without having to adjust any other files because we’ll use the group name elsewhere to reference these hosts.
If you're not familiar with naming your routes take a look at the short section on Routing - Slim Framework. Most modern PHP routing packages and frameworks will support named routes.
Modules & Tasks
Modules are a unit of code executed by Ansible from the control node to the managed node. Modules all have a unique purpose from creating system users to creating databases. At first glance, you might be tempted to use the command module for everything. While you can build playbooks like this it’s not preferred way because commands defined in modules will always be run, even if they don’t need to be run. Think about creating a folder. You can easily run mkdir /some/path via a command module however the next time you run this module the command will throw an error because /some/path will already exist. This is breaking the idempotent goal of Ansible in which we cannot run the same change repeatedly without causing errors or harming the system. Savvy command-line users may say “Well, just use mkdir -p /some/path” which will suppress the error, but we should instead use the file module for managing files and file properties.
An example of ensuring /some/path exists on our managed node we can use the following block which utilizes the file module:
---
- name: Create a directory if it does not exist
file:
path: /some/path
state: directory
mode: ‘0755’
This example is a task in Ansible terms. A task is an item which utilizes a module to accomplish a work item. Tasks should always have a name which is what we see when running the task in the command line execution output so it’s always important to name tasks something easy to understand what is being accomplished. We’re using the file module to create a directory and we’re using path to specify what path we want to ensure exists, the state of that path should be a directory and the permissions mode should be set to 0755. Now our task is idempotent so that each time this task is executed the path will only ever be created once. The next time the task is run Ansible will see the path already exists and do nothing.
It’s important to remember tasks describe the desired state of the managed node. If someone were to go behind us and change the permissions of /some/path to 0777 the next time our task is run the permissions will be changed back to 0755 because our task dictates the desired state to be mode 0755. Ansible will see the path /some/path exists and is a directory but will notice the permission mode does not match our desired state, so Ansible will apply the permissions change. Once you are managing a system with Ansible you should make ALL further changes to the managed node(s) in the same Ansible playbook, task, or role.
If we wanted to remove the /some/path directory we created we could change the state: directory to state: absent to instruct Ansible to ensure the path does not exist the next time the task is executed.
Another common task we will need is to create system users and set specific attributes on the user such as SSH key, groups, etc. To create an unprivileged user account to use for hosting our application we would use the following task:
---
- name: Create application user account
user:
name: appuser
state: present
groups: appuser
shell: /bin/bash
- name: Set authorized keys taken from url
authorized_key:
user: appuser
state: present
key: https://github.com/svpernova09.keys
Now we’ve introduced two new modules: user and authorized_key. We now have two tasks defined to create a user and set the user’s ~/.ssh/authorized_keys file with public keys defined in my Github account. Ansible will create our user and ensure the user is assigned to a group of the same name as our username, and ensure the user’s shell is set to /bin/bash. The next task will download the file https://github.com/svpernova09.keys and copy the contents into /home/appuser/.ssh/authorized_keys which will give me access to SSH into our managed node as the appuser account we just created.
If for some reason I add or remove public keys from my Github account we can simply run the tasks again to update the SSH keys in the users authorized_keys folder. I prefer this method instead of setting passwords for users unless I must set a password for a user, in which we must specify an encrypted password in our task.
What if we needed to remove this user account later? We can easily update our tasks to use state: absent and run them again to remove the user from our managed node. From a version control standpoint, this would be 1 change to set the desired state of the user to absent, instructing Ansible to remove the user account. Once this has been completed we can remove the tasks from our playbook. If we removed our tasks from our playbook before we ran the changes with the state set to absent, Ansible wouldn’t do anything with the user since our tasks affecting appuser would no longer exist. It’s important to remember this step when it comes to removing or undoing changes you’ve previously done.
Roles & Playbooks
So far we’ve stepped through the basics of Ansible which brings us to the point where we start putting everything together. Our tasks are using modules and the next step is to build a role that contains all of our tasks grouped into similar functionality. There is no hard and fast rule about how you group your roles. I think about roles as a group of similar tasks to achieve state for a particular service, feature, or other collection of a state which should be applied. A group of tasks will make up a role while a playbook can be comprised of many roles or just one.
Playbooks are an opinionated way to organize roles and tasks. Convention over configuration is the best path forward. Ansible has a specific folder structure for playbooks which is quite easy to understand. The playbook itself is a YAML file that specifies the hosts to run the role(s) against. Roles are comprised of tasks that give us insight into the full stack of Ansible components to be the Playbook, Roles, Tasks, Modules. When running a playbook we’ll pass options via the command line to execute a playbook file against an inventory file. The command is similar to ansible-playbook -i INVENTORY.ini PLAYBOOK.yml.
We’re going to continue with our example of adding and configuring users to a system by creating a playbook and a role. We’ll name the playbook server-setup.yml and create a role named user-accounts. Our folder structure will be:
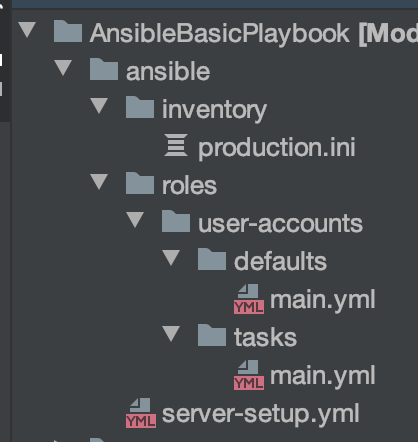
At the top level of our project folder, we create an Ansible folder which will hold the contents of our playbook. We’ll create an inventory file that I name by the environment to describe the contained systems. We’ll use the same inventory file as previously shown. Next, we create a roles folder that will contain all of our roles for all playbooks we may create in this project. We have started to populate our role with all the basics we’ll need which includes defaults/main.yml which will hold any variables our role may need, tasks/main.yml which is where we’ll put all of our roles tasks. Lastly, we have our playbook file in the top-level ansible folder of our project. This project structure is what Ansible expects and breaks up the different parts.
Now that we have built out our files we can dive into the playbook file itself: ansible/server-setup.yml and configure it as:
---
- name: Set up our web servers
hosts: webservers
remote_user: root
vars:
- production: yes
- staging: no
- development: no
roles:
- user-accounts
Breaking down our playbook we define a name to be used during the run time so we can easily tell what’s being run. We then set the host's value to webservers which is the group both of our web application servers are grouped in our inventory file. This tells Ansible to run the playbook against only managed nodes in the specified group. We also define a remote user to perform tasks as. We explicitly state root as the remote user so we operate with the knowledge that everything will be run as the root user unless we use the become keyword later if we need to perform a task as a different user. Next, we’ll define some variables (vars) which will be scoped to this playbook. I tend to use environment names here so I can easily skip items that may need to be done in production but not in other environments. The last part of our playbook is where we define the roles we want to be applied to the hosts. Playbooks require at least one role and the limit is really up to you.
You could also run your playbooks as a default user (such as
vagrantorubuntudepending on the remote system) and then usebecometo switch to root. I normally use root by default as most often I’ll be doing superuser required tasks such as installing packages and configuring services.
We introduced a few new files and folders in our user-accounts roles. Starting with the ansible/roles/user-accounts/tasks/main.yml file we’ll add our tasks here for creating and configuring our users. We’ll copy our two tasks from earlier into this file to create our appuser as well as set the ~/.ssh/authorized_keys contents so we can SSH into our system. At this point we can run our playbook via ansible-playbook -i inventory/production.ini server-setup.yml
One glaring issue with our playbook and role is that we’ve hardcoded our user name into the task itself. We should instead use a variable in our task. We can update our task file to the following to use variables instead of hardcoding it:
---
- name: Create application user account
user:
name: “{{ application_user }}”
state: present
groups: “{{ application_user }}”
shell: /bin/bash
- name: Set authorized keys taken from url
authorized_key:
user: “{{ application_user }}”
state: present
key: https://github.com/svpernova09.keys
We need to use quotes for variables in YAML files or else Ansible will throw an error. Now that we have created our “{{ application_user }}” and we can move our appuser value to the ansible/roles/user-accounts/defaults/main.yml file as:
---
application_user: appuser
This is a special convention Ansible uses to read default variables that are scoped to the role. While scoping variables to the role is not a problem, in this use case where we’re creating and configuring users we may want to move the variables to a higher level (and higher order of precedence) to the playbook. We could delete the ansible/roles/user-accounts/defaults/main.yml file and move our variable into the playbook alongside our other variables:
…
vars:
- application_user: appuser
- production: yes
- staging: no
- development: no
…
When we define variables in the playbook, any role used by the playbook will have access to these variables. Just like variable scope in PHP, Ansible has variable precedence and it can be quite overwhelming to newcomers. Most often I start as close to the role as I can with variables and extract them to the playbook as needed. If I need a variable in multiple playbooks, it may make sense to move these variables to the inventory file. We could specify our application_user variable in an inventory file as:
[webservers]
web-01.domain.tld ansible_host=192.168.42.10 application_user=appuser
web-02.domain.tld ansible_host=192.168.42.11 application_user=appuser
You can define as many variables as you’d like, just ensure they are on the same line as your domain or IP.
Try to avoid overusing variables. It’s ok to repeat yourself for the sake of having clear and concise roles. When you are just starting, stick to using role-based variables. this will be the clearest way to see how variables are used. if you need something more advanced look into inventory variables. Make sure you consult the docs when using variables if you find yourself trying to figure out where a variable comes from
Recap
Now we’ve covered the basics of Ansible and building our first playbook. Next month we’ll dive into part 2 where we’ll put our Ansible knowledge through its paces to build a playbook to configure a blank Ubuntu system to server our PHP application.
Happy Provisioning!
Warning:
This post content may not be current, please double check the official documentation as needed.
This post may also be in an unedited form with grammatical or spelling mistakes, purchase the December 2018 issue from http://phparch.com for the professionally edited version.
As Seen On
Recent Posts
- PHP to Rust via Copilot
- Compiling Python 3.12 from Source Tarball on Linux
- HTML Form Processing with PHP - php[architect] Magazine August 2014
- The Workshop: Local Dev with Lando - php[architect] Magazine November 2022
- Getting back into the swing of things
- All Posts
Categories
- ansible
- apache
- applesilicon
- aws
- blackwidow
- cakephp
- community
- composer
- conferences
- copilot
- data-storage
- day-job
- devops
- docker
- fpv
- general
- github
- givecamp
- homestead
- jigsaw
- joindin
- keyboard
- laravel
- learning
- linux
- maker
- mamp
- mentoring
- music
- nonprofit
- opensource
- packages
- php
- phparch
- projects
- provisioning
- python
- razer
- rust
- s3
- security
- slimphp
- speaking
- static-sites
- storage
- testing
- tiny-whoop
- today-i-learned
- training
- ubuntu
- vagrant
- version-control
- windows
- writing
- wsl
- wsl2
- zend-zray