The Workshop: Real World PDF Generation - php[architect] Magazine September 2019
Joe • September 26, 2020
learning phparch writing phpWarning:
This post content may not be current, please double check the official documentation as needed.
This post may also be in an unedited form with grammatical or spelling mistakes, purchase the September 2019 issue from http://phparch.com for the professionally edited version.
Real World PDF Generation
Last month we covered the basics of PDF generation by focusing on the FPDF library. We generated a custom PDF by placing cells on the page and adding data to those cells. FPDF is a relatively low-level library in comparison to modern libraries which may do more of the heavy lifting for you.
This month we’re going to pick up where we left off with our example application which you can find on Github. Specifically, we’re going to mock up a customer receipt from an imaginary store and deliver this receipt as a PDF to our customer. To accomplish our goal we want to build our source (the page to be turned into a PDF) from HTML/CSS. We’re going to use two different tools since they’re the most common tools I’ve experienced in my career: wkhtmltopdf and using a headless (think command line) Chrome Browser. Neither of these tools is as easy as composer install and jump right into using a package’s code. Both of these tools are outside-of-PHP binaries we’ll pass data to, and get a PDF file back from.
Before we dive right into wkhtmltopdf you should install it on your local system or development environment by downloading a binary from wkhtmltopdf. Since I’m developing local on my MacOS machine using Valet I’m going to use Homebrew to install the package via: brew cask install wkhtmltopdf. Once installed we can use a terminal to play around with wkhtmltopdf to create a PDF from a web site via running the following:
$ wkhtmltopdf http://world.phparch.com php-world.pdf
Loading pages (1/6)
QFont::setPixelSize: Pixel size <= 0 (0) ] 47%
Counting pages (2/6)
QFont::setPixelSize: Pixel size <= 0 (0)=====================] Object 1 of 1
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
We now have the output in PDF form php-world.pdf which we can open in a PDF reader application and see it did a reasonable job in converting a web site into a PDF:
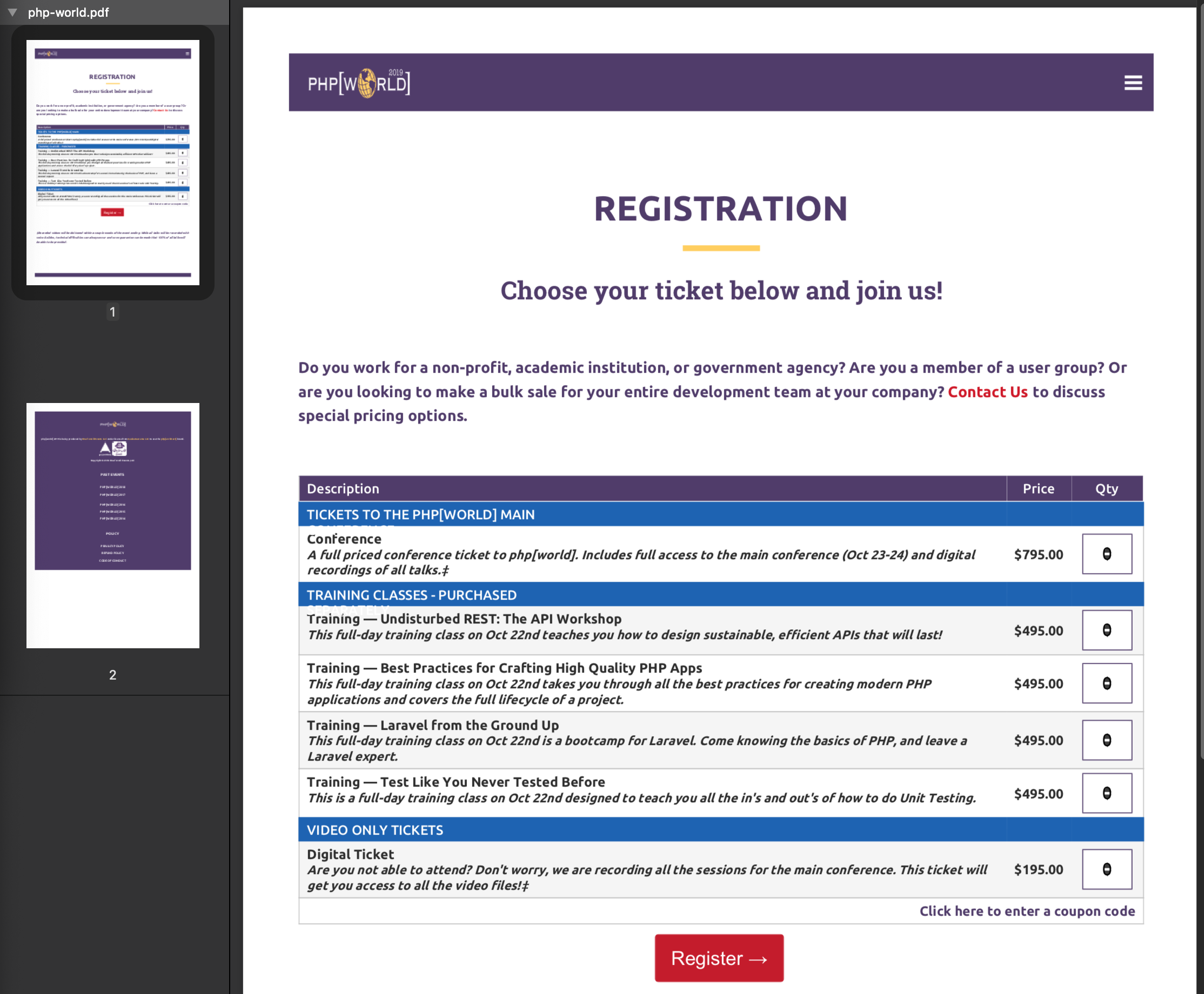
The PDF we created isn’t perfect, but we need to remember we created this from a website designed to be displayed on a screen, not shoved into an 8.5”x11” sheet of paper. The magic of turning HTML into PDFs which look good can be a challenge. This is due to the fallout of the Browser wars - Wikipedia where the major browsers fought tooth and nail to innovate in order to lure users from the other browsers which ultimately caused each browser to render HTML & CSS slightly different as well as pick and choose what they wanted to support or not. Arguably Chrome was the winner as has seemed to take the place as champion browser (for now) which is why we’re also covering “Headless Chrome” and not “Headless Firefox” or “Headless Internet Explorer”.
In our code repository if we inspect resources/views/receipt.blade.php we’ll find an HTML, CSS, and JavaScript view built using Bootstrap containing a completely fake receipt from phparch.com. In our example we can see our customer “Montgomery Burns* has purchased my two favorite books as well as a subscription to the php[architect] magazine. This view will serve as our customer’s receipt or invoice for their purchase. Because receipts and invoices are formal documentation of a purchase or exchange we should ensure the readability across platforms and devices: the ideal solution for creating a PDF version the customer can download, and we can archive for our own records.
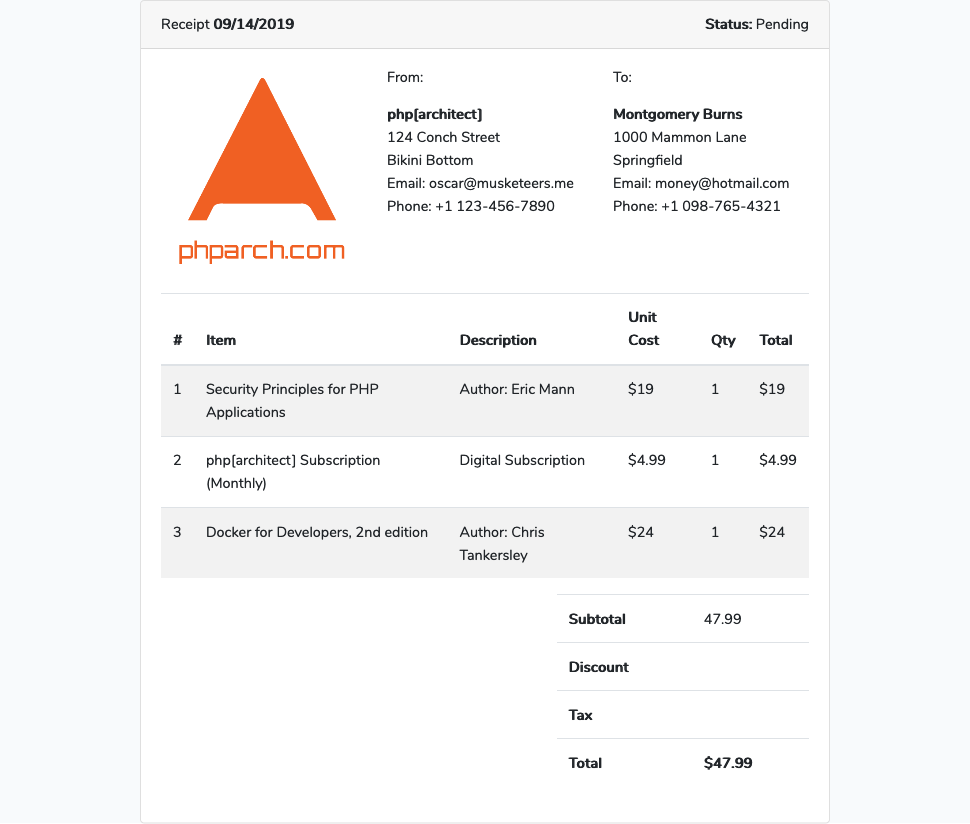
To automatically create a PDF from this view, we need to render our HTML but instead of sending it back to the browser as a response, we want to pass our HTML to wkhtmltopdf and return the PDF output to the browser. Remember we installed a binary wkhtmltopdf on our system so we don’t have access to any class or library to access directly. A common approach to this solution is to use exec() to “shell out” or to pass information from our application to a shell (terminal). In our example, we’ll pass the HTML of our view to the wkhtmltopdf along with a destination path so we can store the PDF locally. This will allow us to also capture the exit code of the command we run so we can determine if our PDF generation command was completed successfully or ran into an issue.
All applications return an ‘exit-code’, which is an integer result of the command. Normally a successful command will return exit code
0, while unsuccessful commands will return a non-zero value which is usually a reference to more information about the particular fault or error state occurred. You can read more about exit codes in the Advanced Bash-Scripting Guide
Whenever we “leave” our application via exec() things can get weird.
Specifically, because PHP won’t know much about what was done other than what we can inspect and assume from the exit code of the command we’ve run. We should also be aware PDF generation can be an incredibly taxing operation for a server, especially if you’re doing hundreds or thousands of pages. If you are generating PDFs this large my advice would be to build (or refactor) into a job queue architecture where you could kick off a job to build a PDF and get a notification back to the application when the process has been completed. This way PDF generation will not block your application for long periods of time. Application blocking becomes a big concern when using exec() because our application will not continue past the command we execute until the command completes or throws an error. This is especially important to remember in the context of HTTP requests which have a relatively short lifespan.
The process we’re going to follow will be to render a view and save the output to an HTML file on the filesystem. We’ll check the exit code from the command to ensure success before sending the generated PDF as a response. In order for us to capture the exit code of our command we need to pass pass two additional parameters to the exec function after our command: $output which can be an existing array which will have ALL of the lines of the command output appended to, in our use case we’ll just pass in an empty array. The second additional parameter is a variable which PHP will use to store the exit code. We’ll set this variable as null so we can verify the exit code is 0 which signals to our application the command completed successfully. We’re also going to pass some parameters to our command: -s Letter —no-background -L 2 -R 2 which translates into the letter-size document with no background, with 2mm margins on the left and right sides. You can see the entire list of parameters and options of wkhtmltopdf
Our code could look something similar to:
```
public function createPdf(Request $request)
{
$filename = time().'-receipt.html';
# render our view
$html = view('receipt')->render();
# save the HTML to a file
file_put_contents(storage_path().'/'.$filename, $html);
# specify params
$params = '-s Letter --no-background -L 2 -R 2';
# Run the wkhtmltopdf binary
$command = 'wkhtmltopdf '.$params.' '.storage_path().'/'.$filename.' '.storage_path().'/receipt.pdf';
$output = [];
$exit_code = null;
exec($command, $output, $exit_code);
if ($exit_code == '0')
{
return Response::make(file_get_contents(storage_path().'/receipt.pdf'), 200, [
'Content-Type' => 'application/pdf',
]);
}
exit();
```
We’re using
storage_pathwhich is a Laravel helper method to return the path to thestoragefolder in the application. This path will be the full system path to the storage folder, in my case “ /Users/halo/Code/create-pdf/storage/”.
The full command we’re executing is ”wkhtmltopdf /Users/halo/Code/create-pdf/storage/1565814447-reciept.html /Users/halo/Code/create-pdf/storage/receipt.pdf”
As long as our exit code is 0 we should see a PDF in our browser when we reload our page:
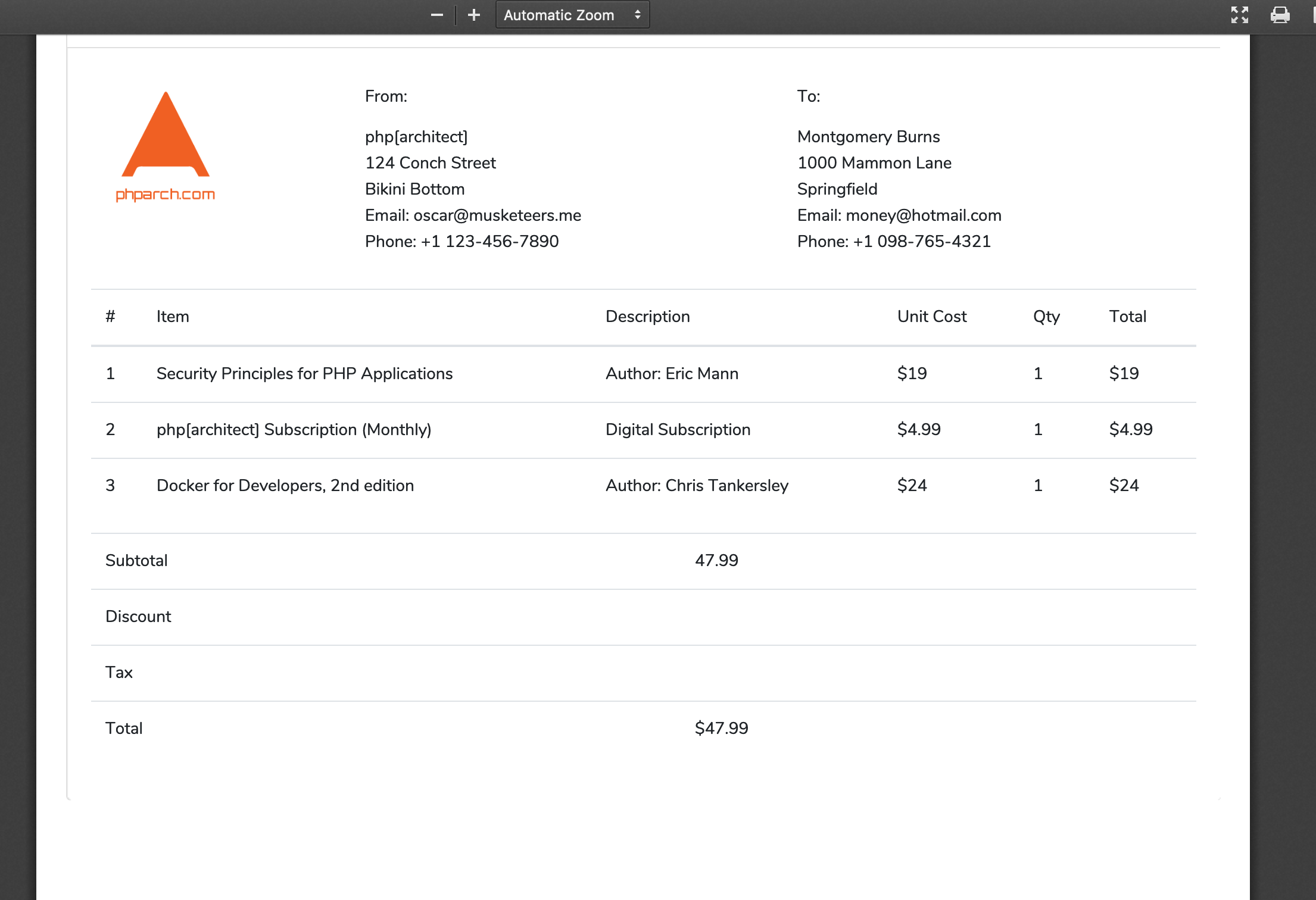
Now we have given our user a copy of their receipt they can easily save or print. We could have also saved a copy of the PDF to our own document store, but for the purposes of this example, we still have the PDF located at storage/receipt.pdf in our project. Our PDF isn’t perfect, there are a few design flaws such as the right border missing and our bottom totals isn’t right aligned. In order to fix these issues we’d have to also change these <div> elements to tables as we have with our header and item list sections. The true reality is PDF generation is just as painful as formatting any document for print or email. In our example we’ve reused a web view to just display information to a user in a browser to also serve as the source of our PDF. For the best results where the final output is very important to have near-perfect styles, my recommendation is to use a custom view specifically for PDF generation.
Browsershot and Headless Chrome
spatie/browsershot is a fantastic package by the great team at Spatie in Belgium. They give back an incredible amount to the PHP ecosystem in the form of packages to easily accomplish tedious application logic most often in their specialty: the Laravel framework. The Browsershot package will allow us to save our rendered HTML in a much more fluent interface than having to use exec(). While Browsershot still leverages outside-of-our-application binaries like our previous example did with wkhtmltopdf, we don’t have to write the code!
Requirements
Browsershot relies on a NodeJS package called GoogleChrome/puppeteer which gives us a programmatic interface to a headless version of the Google Chrome browser. Before we continue we need to install puppeteer into our project via npm install puppeteer. I already have NodeJS installed via Homebrew on my system, so we’re ready to go there. The last thing to do is to add the Browsershot package itself to our application via composer require spatie/browsershot
Remember we need to ensure these same binaries are available to be used on the production system whoever this code will be running from!
Now we have configured the requirements for the Browsershot package on our system we are ready to start writing code. We’re going to reuse the same view we previously used with wkhtmltopdf but since Browsershot can access HTML directly, we can skip the step of writing our HTML rendered view to the filesystem.
```
public function createPdf(Request $request)
{
# render our view
$html = view('receipt')->render();
$path = storage_path().'/'.time().'-receipt.pdf';
Browsershot::html($html)->save($path);
if (is_file($path)) {
return Response::make(file_get_contents($path), 200, [
'Content-Type' => 'application/pdf',
]);
}
exit();
}
```
All of the extra code we needed to shell() our wkhtmltopdf can be simplified down to Browsershot::html($html)->save($path); We’re telling Browsershot to take our $html content and to save it to the $path we created. Since our path ends with .pdf Browsershot knows to convert to a PDF file.
You can also save a PNG image by specifying a path and filename and .png extension. Saving an image is another feature of Puppeteer the Browsershot package is giving us access to. We can also resize the image and perform manipulations such as clipping as well as increasing the quality of the image by using ->setScreenshotType(‘jpeg’, 100)
Inspecting our PDF which was created by Browsershot we can see it was rendered better than wkhtmltopdf because we’re not missing any of our borders and our totals section is back over on the right side instead of the left:
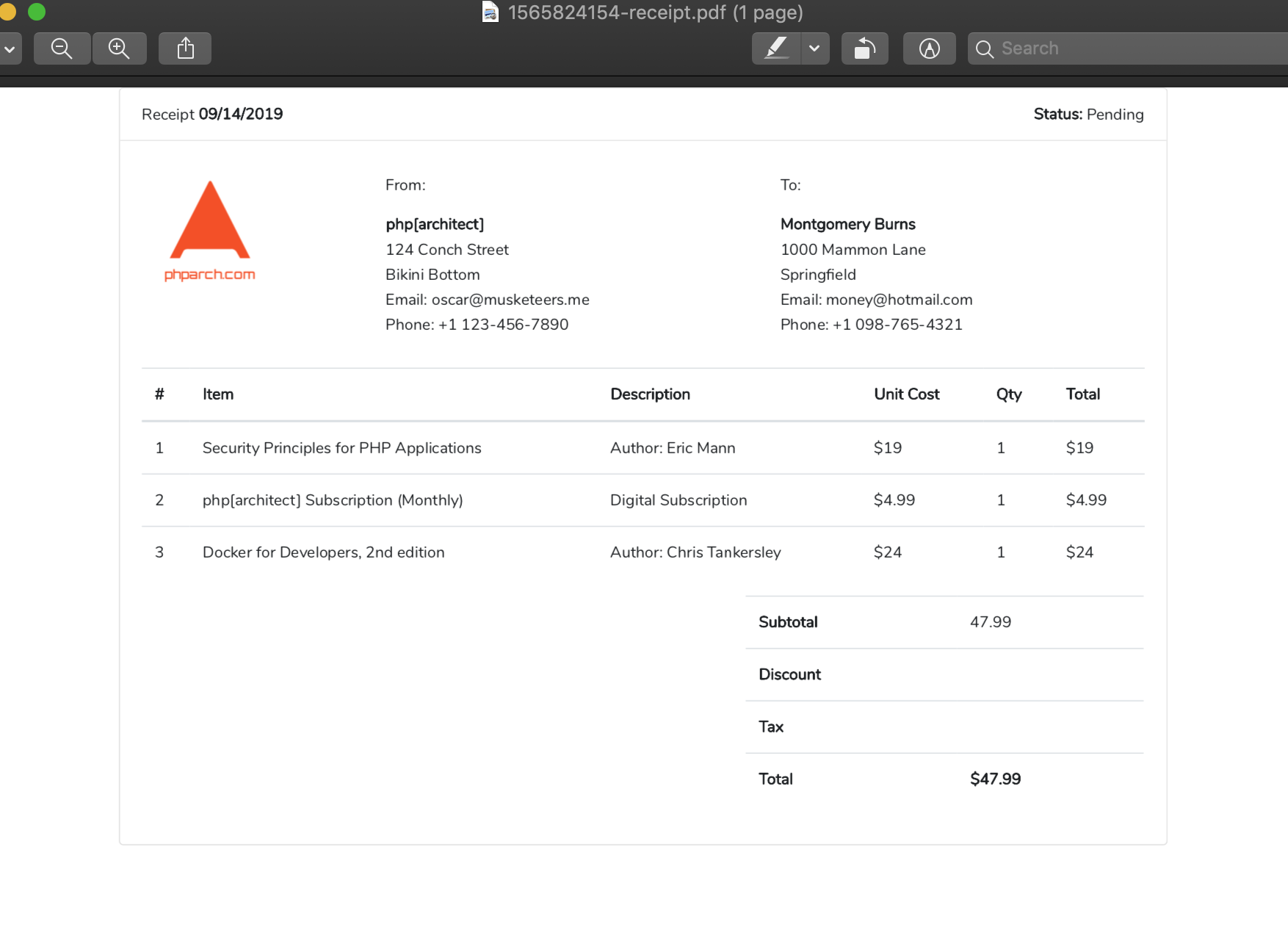
Remember to be aware of how long these requests are taking if it takes longer than 10-20 seconds to generate the PDF we could be running into execution time limits. When this happens we should refactor into a job queue as described earlier so we don’t have our application waiting on a large PDF to be created.
What’s the best option?
Between FPDF, wkhtmltopdf, or Browsershot (which relies on Puppeteer & Google Chrome) my advice is if you’re not a designer and want to bring your existing web styles to PDFs: start with Browsershot or any other package which leverages a headless browser. It makes sense the browser did the best job rendering our HTML * we designed for the web* into a PDF file.
I believe it’s impossible to write about headless browsers and not at least mention Selenium - Web Browser Automation. Selenium has been doing headless rendering for a really long time. The pain point of Selenium are it’s complicated configuration options. Early HTML rendering applications would use Selenium as a fake browser because it rendered content so well. If you get started with wkhtmltopdf or Browsershot and need more control over the output you might want to invest some time into Selenium. For those developers who need a quick drop-in solution: Browsershot/Puppeteer is my first recommendation.
Paid Solutions
We’ve only covered free (as in beer) solutions, however there are some really great options out there if you need more features or something to fit better into your current application workflow. One solution I have some (now dated) experience with is DocRaptor: HTML to PDF API. I used this at a previous day job to do on-demand PDF generation for a range of different customers. Mostly it was for newsletter creation or as in our fictitious example: invoices and receipts. One of the specific reasons we used DocRaptor was due to the requirement to convert HTML which contained JavaScript charts and visualizations into PDF. Many of the common open-source/free tools break down at this type of workload. DocRaptor is just like communicating with any other API service from the application standpoint: build the HTML and send it off to their API, and you will receive a PDF as a response. This solution was very robust and fault-tolerant for the use case of dynamically generating PDFs with content to be specific to the individual viewer.
A second option I came across is Prince - Convert HTML to PDF with CSS. I’ve never tried Prince however based on their samples and documentation it looks to be a fantastic option. If you run into issues with your own PDF generation implementation I highly suggest you look into a paid solution. A paid solution may be cheaper in the long run instead of you having to spin up infrastructure to support your own PDF creation process as we’ve shown here.
Happy Coding (and PDF generating!)
Warning:
This post content may not be current, please double check the official documentation as needed.
This post may also be in an unedited form with grammatical or spelling mistakes, purchase the September 2019 issue from http://phparch.com for the professionally edited version.
As Seen On
Recent Posts
- PHP to Rust via Copilot
- Compiling Python 3.12 from Source Tarball on Linux
- HTML Form Processing with PHP - php[architect] Magazine August 2014
- The Workshop: Local Dev with Lando - php[architect] Magazine November 2022
- Getting back into the swing of things
- All Posts
Categories
- ansible
- apache
- applesilicon
- aws
- blackwidow
- cakephp
- community
- composer
- conferences
- copilot
- data-storage
- day-job
- devops
- docker
- fpv
- general
- github
- givecamp
- homestead
- jigsaw
- joindin
- keyboard
- laravel
- learning
- linux
- maker
- mamp
- mentoring
- music
- nonprofit
- opensource
- packages
- php
- phparch
- projects
- provisioning
- python
- razer
- rust
- s3
- security
- slimphp
- speaking
- static-sites
- storage
- testing
- tiny-whoop
- today-i-learned
- training
- ubuntu
- vagrant
- version-control
- windows
- writing
- wsl
- wsl2
- zend-zray